ผมสองจิตสองใจอยู่นาน ว่าจะเริ่มต้นบทความนี้จากการสรุปรวบยอดไอเดียทั้งหมด หรือจะอธิบายส่วนประกอบต่างๆโดยละเอียดดี เมื่อไม่แน่ใจก็จะขอทำตามที่ผู้รู้หลายๆท่านทำคืออธิบายอย่างละเอียดก่อน หากผู้อ่านคนไหนรู้สึกว่า เนื้อหาส่วนรายละเอียดยืดยาวหรือมีความรู้เบื้องต้นอยู่แล้ว สามารถกระโดดข้ามไปอ่านส่วนท้ายของบทความก่อนได้เลยครับ
Node(s) คือเครื่อง Server ซึ่งแต่ละเครื่องไม่จำเป็นต้องมี Spec เหมือนกัน โดยพื้นฐานแต่ละเครื่องจะรายงานจำนวน ซีพียู Core และขนาดของหน่วยความจำ (RAM) คุณสมบัติพิเศษบางอย่างเช่น การ์ด GPU สามารถถูกกำหนดเข้าไปอยู่ใน Spec ของ Node เพื่อใช้เลือกว่าจะรันงานไหนในเครื่องไหนได้
ซีพียูแต่ละ Virtual Core จะถูกนับใน Kubernetes เป็น 1,000 unit หรือ 1,000 milicore เช่น Node_0 จะมี ซีพียู 8,000 milicore

Nodes
Cluster คือการที่เครื่อง Server ตั้งแต่หนึ่งเครื่องขึ้นไป เข้ามาร่วมมือกัน ตกลงกัน แสดงความเป็นเอกภาพในการทำงานร่วมกัน (Represent) รูปด้านล่างใช้หน่วย milicore เพื่อแสดงจำนวนซีพียู ซึ่งจำนวนซีพียูและหน่วยความจำของ Cluster มาจากผลรวมจากของทุกๆเครื่องที่อยู่ใน Cluster

Cluster
Persistent Volume (PV) เป็นเสมือนฮาร์ดดิสก์ที่ต่อเข้าไปในแต่ละ Pod บางประเภท PV ขึ้นอยู่กับ Node (์Node-bound) บางประเภทสามารถย้ายข้าม Node ได้ (สำหรับกรณี Pod ย้ายจาก Node นึงไปอีก Node นึง) กรณีหลังจะคล้ายๆกับ iSCSI ใช้บน Cloud สะดวกมากๆๆ

Persistent Volume
Pod เป็นหน่วยการทำงานที่เล็กที่สุดของ Kubernetes ถ้าเราต้องการจะรัน Container เล็กๆซักอันนึง เราต้องเอา Container ของเรายัดเข้าไปใน Pod ก่อนถึงจะรันได้
เราอาจจะมองว่า Container เป็นเมล็ดถั่วลิสง และ Pod เป็นเปลือกของถั่ว ในเปลือกถั่วลิสงหนึ่งเปลือกอาจจะมีเมล็ดได้หลายเมล็ด

Peanut — from Pixabay

Pod
ถึงจุดนี้ คนที่เคยใช้ Docker Compose มาก่อน อาจจะเข้าใจผิดและมอง Pod เป็นการรวมหลายๆส่วนของ App ไว้ด้วยกัน เช่น Frontend + Business Logic + Datastore แบบใน Docker Compose ใน Kubernetes เราจะใช้วิธีอื่น (Deployment กับ Service)
Container ที่ควรจะรวมอยู่ภายใน Pod เดียวกันคือ (1) Container ที่จำเป็นต้องทำงานร่วมกัน และ/หรือ (2) ควรที่จะขยาย (scale out) หรือ ลดจำนวน (scale in) ไปด้วยกัน ตัวอย่างที่เห็นบ่อยๆคือ Sidecar Container (คล้ายๆกับมีดสวิส — เอาไว้บริหารจัดการ Container หลัก) หรือ Metrics Container (เอาไว้จัดการข้อมูลสำหรับใช้ตรวจสอบและดูแลระบบ)
สาเหตุที่ตัวอย่างก่อนหน้าที่ Frontend + Business Logic + Datastore ไม่ควรอยู่ใน Pod เดียวกันเพราะว่า ในแต่ละส่วน (Layer) ควรจะขยายหรือลดจำนวนแบบตัวใครตัวมัน ถ้ามีคนเปิดหน้าเว็บเยอะๆก็ควรขยายแค่จำนวน Frontend อย่างเดียว ไม่จำเป็นต้องขยายส่วนอื่นให้เปลืองทรัพยากร หรือถ้าจะอัพเกรดเวอร์ชั่น Frontend ก็ไม่จำเป็นจะต้องติดตั้ง Business Logic ใหม่ (ซึ่งถ้าอยู่ใน Pod เดียวกันจะต้องติดตั้งไปพร้อมกันเสมอ)
ถ้าใครมาจากสาย Software Development เรื่องการจะตัดสินใจว่า Container ไหนควรจะอยู่ด้วยกันจะคล้ายๆกับ Single Responsibility Principle (SRP) ของ SOLID Design Principle
Deployment — ในการใช้งานจริง เราจะไม่ประกาศและติดตั้ง Pod ตรงๆ (Naked Pod) เพราะว่าถ้าเราติดตั้ง Pod ตรงๆ เมื่อ Pod นั้นมีปัญหาและหยุดการทำงาน Kubernetes จะไม่จัดการอะไรให้เรา เราจะต้องมาติดตั้ง Pod นั้นใหม่เองอีกครั้ง
แต่ถ้าเราใช้ Deployment เมื่อ Pod ไหนหยุดการทำงาน Kubernetes จะติดตั้ง Pod ใหม่มาแทนที่ให้อัตโนมัติ จนกว่าจะครบตามจำนวนที่ต้องการ (Replicas)

Deployment
อีกเรื่องหนึ่งที่อยากเสริมเพราะหลายๆคนอาจจะยังไม่รู้คือ Deployment ไม่ได้ติดตั้ง Pod เองตรงๆ แต่จะติดตั้งตัวกลางอันหนึ่งชื่อ ReplicaSet ซึ่งในแต่ละ Deployment สามารถมี ReplicaSet ได้หลายอัน แต่จะมี Active ReplicaSet แค่อันเดียว
แล้วจะทำให้ซับซ้อนทำไม? เจ้า ReplicaSet เนี่ยช่วยให้เราสามารถ Roll out และ Roll back ได้ โดยเมื่อเรา Roll out เวอร์ชั่นใหม่ (Image Tag ใหม่) Deployment จะสร้าง ReplicaSet อันใหม่ และถ้าเราเห็นว่ามันไม่โอเค จะ Roll back กลับไปเวอร์ชั่นก่อนหน้า Deployment ก็จะสลับกลับไปใช้ ReplicaSet เดิม
ใน Kubernetes ยังมีการประกาศและติดตั้ง Pod อีกหลายแบบตามลักษณะการทำงานที่เหมาะสม
- Deployment — เหมาะสำหรับงานที่แต่ละ Pod ทำงานเป็นอิสระจากกัน (Stateless)
- StatefulSet — เหมาะกับงานที่แต่ละ Pod มีลำดับ (1 2 3) หรือบทบาทต่างกัน
- DaemonSet — เหมาะกับงานที่ตั้งใจให้รันในทุกๆ Node เช่น การเก็บ log หรือ เก็บ Metrics
- ReplicationController — คล้ายๆกับ Deployment แต่ไม่แนะนำให้ใช้แล้ว
- ReplicaSet — คล้ายๆกับ Deployment ปกติแล้วจะใช้ Deployment และให้ Deployment สร้าง ReplicaSet อีกที
- Job— เหมาะกับการรันงาน Batch สามารถ retry ถ้าการทำงาน fail สามารถรัน parallel ได้
- CronJob — ใช้สำหรับ Schedule Job อีกที
Service เป็น Load Balancer โดนทำหน้าที่หลักสองอย่างคือ 1) เป็นตัวแทนงานบริการ (Server) ซึ่งรวมถึงการประกาศชื่อของงานและการรับงานเข้ามา และ 2) กระจายงานที่รับมาส่งต่อให้แต่ละ Pod

Service
จากรูป จะดูเหมือน Service ส่งงานให้ Deployment แต่จริงๆแล้ว Service ใช้ Deployment แค่เพื่อหาลิสต์ของ Pod ที่สามารถส่งงาน (Request) ต่อไปให้เท่านั้น (Endpoint) Service จะส่งงานให้เฉพาะ Pod ที่พร้อมทำงานเท่านั้น (มีการ Probe) แต่ละ Service จะต้องบอกว่าจะส่งต่องานไปให้ Pod ของ Deployment โดยการใช้ฟิลด์ Selector
สรุปรวบยอดข้อมูลที่จำเป็นต้องรู้เกี่ยวกับ Kubernetes นะครับ มีทั้งที่บอกไปแล้วและที่ยังไม่ได้พูดถึงก่อนหน้า
- หน่วยทำงานเล็กสุดคือ Pod และในนั้นก็จะมี Container ตามที่เราประกาศไว้
- ปกติเราไม่ติดตั้ง Pod แต่จะใช้การประกาศ Deployment หรือสิ่งที่คล้ายคลึง (เช่น StatefulSet)
- เราใช้ Label และ Label Selector เพื่อโยงความสัมพันธ์ระหว่างประเภทของ Resource เช่น บอกว่า Service จะส่งงานต่อให้ Deployment ไหน หรือบอกว่า Pod ไหนอยู่ใต้การดูแลของ Deployment/ReplicaSet ไหน
- การติดต่อระหว่าง Layer ต่างๆ หรือ Microservice ต่างๆ จะใช้ผ่าน Service ไม่ใช่การคุยตรงๆระหว่าง Pod ซึ่งสามารถใช้ Service เพื่อทำ Load Balance ได้ด้วย
- ควรใช้ Namespace เพื่อแบ่งขอบเขตของกลุ่มงาน (Isolate) เช่น แบ่งระบบ HR ออกจากระบบบัญชี หรือ ระหว่าง Testing กับ Development
- ใช้ Persistent Volume เพื่อเก็บข้อมูล ถ้า Pod หยุดการทำงาน Pod ที่มาแทนที่สามารถ Mount และทำงานต่อได้เลย
- การสั่งงาน Kubernetes มีสองแบบ คือ สั่ง (Imperative) กับ บอกความต้องการ (Declarative)
- ควรใช้ Secrets และ ConfigMap เพื่อจัดการ Configuration หรือ พารามิเตอร์ที่จำเป็นของ App เช่น ใช้ Secrets เก็บ Username และ Password ของ Database และใช้ ConfigMap เก็บ URL ของ CDN
- ควรใช้ RBAC เพื่อกำหนดสิทธิ์
- การทำ Autoscalability และ High-Availability ต้องพิจารณาทั้งใจชั้นของ Pod จนไปถึงชั้นของ Node
- อีกหน่อยจะมีเรื่องการใช้ Ingress เพื่อจัดการงาน (Request) ที่มาจากนอก Cluster ต่อไปให้ยังแต่ละ Service
ส่วนนี้จะลึกหน่อย ถ้ารู้สึกว่าลึกไป อ่านๆข้ามๆเอาแค่พอผ่านหูผ่านตาก็พอ
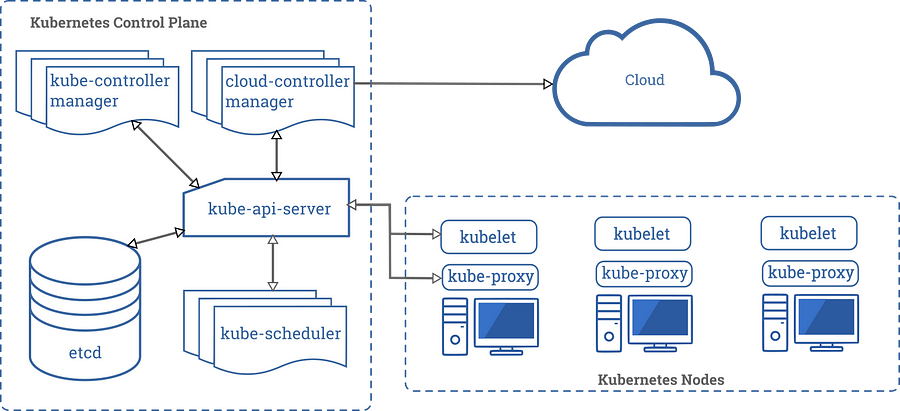
Kubernetes Components – รูปจาก kubernetes.io
- โดยปกติแล้ว Node จะมีอย่างน้องสองประเภทคือ Master (บางทีก็เรียกว่า Control Plane) และ Node (Worker Plane)
- Control Plane ประกอบไปด้วย apiserver, controller-manager, scheduler และ etcd
- etcd เอาไว้เก็บข้อมูลทุกอย่างที่เกี่ยวกับ Kubernetes สำคัญมากๆ ถ้าพังก็พังหมด
- แต่ละ Worker Node จะต้องมี kubelet เพื่อเข้าร่วม Cluster และ kube-proxy เพื่อจัดการการส่งต่อ/รับ traffic
- เราอาจจะใช้ Docker หรือ Container Run-time ตัวอื่นก็ได้
- การติดตั้ง Kubernetes มีหลายวิธี เช่น แบบโหด (manual — kubernetes-the-hard-way) แบบใช้ script ช่วย (kops) แบบง่าย (microk8s) แบบ 3rd-party (OpenShift, Rancher, AKS, GKE, EKS)
- Persistent Volume และ Network มีให้เลือกหลายแบบ และเป็นการติดตั้งแบบ Addons หรือ Plugins ตามทฤษฎีแล้วควรจะสลับไปๆมาได้ แต่ที่เล่นๆมา เวลาสลับ Network Plugins มีโอกาสมีปัญหาสูงมาก
ความจริงไม่มีเวอร์ชั่น แต่โซลูชั่นมีมากกว่าหนึ่งเสมอ


